本文共 5032 字,大约阅读时间需要 16 分钟。
目录
■ 线程wait和sleep相同点和不同点
1. 共同点
1) 都可以让线程处于冻结状态
2) 都运行在多线程环境下,都可以在程序的调用处阻塞指定的毫秒数
Thread thread = new Thread();thread.sleep(10000);Object object = new Object();object.wait(1000);
3)wait()和sleep()都可以通过interrupt()方法打断程序的暂停状态,从而使线程立刻抛出InterruptedException
如果线程A希望立即结束线程B,则可以对线程B对应的Thread实例调用interrupt方法。如果此刻线程B正在wait/sleep/join,则线程B会立刻抛出InterruptedException,在catch() {} 中直接return即可安全地结束线程。
需要注意的是,InterruptedException是线程自己从内部抛出的,并不是interrupt()方法抛出的。对某一线程调用 interrupt()时,如果该线程正在执行普通的代码,那么该线程根本就不会抛出InterruptedException。但是,一旦该线程进入到 wait()/sleep()/join()后,就会立刻抛出InterruptedException。
public class ThreadDemo6{ public static void main(String[] args) { ThreadTest test = new ThreadTest(); Thread thread_1 = new Thread(test); thread_1.start(); thread_1.interrupt(); try { Thread.sleep(1000); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println("程序继续执行。。。"); }}class ThreadTest implements Runnable{ @Override public void run() { try { synchronized (this) { wait(); } } catch (InterruptedException e) { e.printStackTrace(); System.out.println(Thread.currentThread().getName() + "正常退出"); return; } }} 
2. 不同点
1) wait,notify和notifyAll只能在同步控制方法或者同步控制块里面使用,而sleep可以在任何地方使用
wait()和notify()对对象的“锁标志”进行操作,所以它们必须在同步控制方法或者同步控制块中进行调用。如果在non-synchronized函数或non-synchronizedblock中进行调用,虽然能编译通过,但在运行时会发生illegalMonitorStateException的异常。
2) sleep方法属于Thread类中方法,表示让一个线程进入睡眠状态,等待一定的时间之后,自动醒来进入到可运行状态,不会马上进入运行状态,因为线程调度机制恢复线程的运行也需要时间,一个线程对象调用了sleep方法之后,并不会释放他所持有的所有对象锁,所以也就不会影响其他进程对象的运行。
3) wait属于Object的成员方法,一旦一个对象调用了wait方法,必须要采用notify()和notifyAll()方法唤醒该进程;如果线程拥有某个或某些对象的同步锁,那么在调用了wait()后,这个线程就会释放它持有的所有同步资源,而不限于这个被调用了wait()方法的对象。
■ 为什么start调用run方法,调用run不会调用start方法
1. start()方法
通过该方法启动线程的同时也创建了一个线程,真正实现了多线程。无需等待run()方法中的代码执行完毕,就可以接着执行下面的代码。此时start()的这个线程处于就绪状态,当得到CPU的时间片后就会执行其中的run()方法。这个run()方法包含了要执行的这个线程的内容,run()方法运行结束,此线程也就终止了。
2. run方法
通过run方法启动线程其实就是调用一个类中的方法,当作普通的方法的方式调用。并没有创建一个线程,程序中依旧只有一个主线程,必须等到run()方法里面的代码执行完毕,才会继续执行下面的代码,这样就没有达到写线程的目的。
■ 手写单例模式中的懒汉式和饿汉
参考至:
1. 饿汉式
public class Singleton_1 { // 类加载时直接加载该对象,天然线程安全 private static Singleton_1 singleton_1 = new Singleton_1(); // 构造函数私有化 private Singleton_1() {} // 提供一个对外的访问方法 public static Singleton_1 getInstance() { return singleton_1; }} 2. 懒汉式
public class Singleton_2 { // 类初始化时,不加载对象,使用时再加载 private static Singleton_2 singleton_2 = null; // 私有化构造函数 private Singleton_2() {} // 提供一个对外的访问方法,方法同步 public synchronized static Singleton_2 getInstance() { if (singleton_2 == null) { singleton_2 = new Singleton_2(); } return singleton_2; }}
■ transient 这个关键字是干嘛的
参考至:
1. 用途
我们知道,当一个类实现了Serilizable接口,这个类的所有属性和方法都会自动序列化。而在开发过程中,我们可能要求:当对象被序列化时,有些属性需要序列化,而其他属性不需要被序列化,如用户的一些敏感信息(身份证号、密码,银行卡号等),为了安全起见,不希望在网络操作中被传输,这些信息对应的变量就可以加上transient关键字。换句话说,这个字段的生命周期仅存于调用者的内存中而不会写到磁盘里持久化。
所以,transient的用途在于:阻止实例中那些用此关键字声明的变量持久化;当对象被反序列化时(从源文件读取字节序列进行重构),这样的实例变量值不会被持久化和恢复。
2. 小结
1) 一旦变量被transient修饰,变量将不再是对象持久化的一部分,该变量内容在序列化后无法获得访问(null或者空)
2) transient关键字只能修饰变量,而不能修饰方法和类
注意,本地变量是不能被transient关键字修饰的。变量如果是用户自定义类变量,则该类需要实现Serializable接口。
3) 被transient关键字修饰的变量不再能被序列化,一个静态变量不管是否被transient修饰,均不能被序列化
反序列化后类中static型变量的值为当前JVM中对应static变量的值,这个值是JVM中的不是反序列化得出的。
4)补充:序列化和反序列化
序列化:指把堆内存中的 Java 对象数据,通过某种方式把对象存储到磁盘文件中或者传递给其他网络节点(在网络上传输)。这个过程称为序列化。通俗来说就是将数据结构或对象转换成二进制串的过程。
myBatis实现二级缓存以及使用Dubbo+Zookeeper进行分布式开发时,实体类需实现序列化。
反序列化:把磁盘文件中的对象数据或者把网络节点上的对象数据,恢复成Java对象模型的过程。也就是将在序列化过程中所生成的二进制串转换成数据结构或者对象的过程。
反序列化时,不能匹配的值时,会自动赋予初始值。
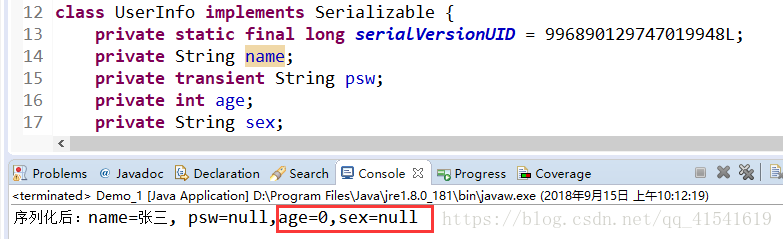
例如有一个UserInfo对象,首次序列化时,只有name和pwd属性,当我反序列化拿数据的时候,再给UserInfo添加两个新的属性age和sex,获取userInfo对象,没有匹配到的值,会默认赋初值。
■ 什么是一致性hash算法
参考至:
1. Redis集群的使用
为保证Redis的高可用,提高Redis的读写性能,会做主从复制或者搭建Redis集群,进行数据的读写分离。
按照我们约定的规则进行分库,规则就是随机分配,我们可以部署8台缓存服务器,每台服务器大概含有500W条数据,并且进行主从复制。查找时,会遍历所有Redis服务器,显然不是我们想要的。
2. 为Redis集群使用Hash
使用类似于数据库的分库分表,采用Hash的方式,每一张图片在进行分库的时候都可以定位到特定的服务器。
公式:hash(服务器名称)%服务器数
缺陷:主要体现在服务器数量变动的时候,所有缓存的位置都要发生改变,所有缓存在一定时间内是失效的,当应用无法从缓存中获取数据时,则会向后端数据库请求数据(缓存雪崩)。
3. 一致性Hash算法
一致性Hash算法对于节点的增减都只需重定位环空间中的一小部分数据,具有较好的容错性和可扩展性。
公式:hash(图片名称)%2^32
Hash环的数据倾斜问题:一致性Hash算法在服务节点太少时,容易因为节点分布不均匀而造成数据倾斜(被缓存的对象大部分集中缓存在某一台服务器上)问题,引入虚拟节点机制解决。
■ 构造方法链
构造一个类的实例时, 将会调用沿着继承链的所有父类的构造方法。 当构造一个子类的对象时,子类构造方法会在完成自己的任务之前,首先调用它的父类的构造方法。如果父类继承自其他类,那么父类构造方法又会在完成自己的任务之前,调用它自己的父类的构造方法。这个过程持续到沿着这个继承体系结构的最后一个构造方法被调用为止。
■ 谈谈你对线程调度的理解
谁调度:CPU调度
1. 概念
计算机通常只有一个CPU, 在任意时刻只能执行一条机器指令, 每个线程只有获得CPU的使用权才能执行指令。 所谓多线程的并发运行, 其实是指从宏观上看, 各个线程轮流获得CPU的使用权, 分别执行各自的任务。在运行池中, 会有多个处于就绪状态的线程在等待CPU, 线程调度是指按照特定机制为多个线程分配CPU的使用权。
2. 两种调度模型:分时调度模型和抢占式调度模型
1) 分时调度模型是指让所有的线程轮流获得CPU的使用权, 并且平均分配每个线程占用的CPU的时间片。
2) 抢占式调度模型是指优先让可运行池中优先级高的线程占用CPU,如果可运行池中的线程优先级相同,那么就随机选择一个线程,使其占用CPU。处于运行状态的线程会一直运行,直至它不得不放弃CPU。
■ JDK动态代理和CGLIB动态代理
案例:
1. JDK动态代理只能对实现了接口的类生成代理,而不能针对类
实现InvocationHandler接口,重写invoke()方法
2. CGLIB是针对类实现代理,其原理是通过目标类的字节码为一个类创建子类,并在子类中采用方法拦截的技术拦截所有父类方法的调用,顺势织入横切逻辑。
实现MethodInterceptor接口,重写intercept()方法
Enhancer,主要增强类,通过字节码技术动态创建委托类的子类实例
setSuperClass(),进行代理,设置需要创建子类的类
setCallback(),设置织入逻辑
create(),生成代理实例
invokeSuper(),通过代理类调用父类的方法
3. Spring AOP是基于动态代理实现的
AOP默认使用JDK动态代理,当目标类没有实现接口时,使用CGLIB动态代理,可以强制使用CGLIB动态代理(在spring配置中加入<aop:aspectj-autoproxy proxy-target-class="true"/>)